当Agent框架走到分叉口:我从OpenClaw切到Hermes的那些技术与权衡
2026年第一季度结束的时候,我发现自己已经连续三个月在同一个问题上反复纠结:手里的Agent项目到底该用哪个框架。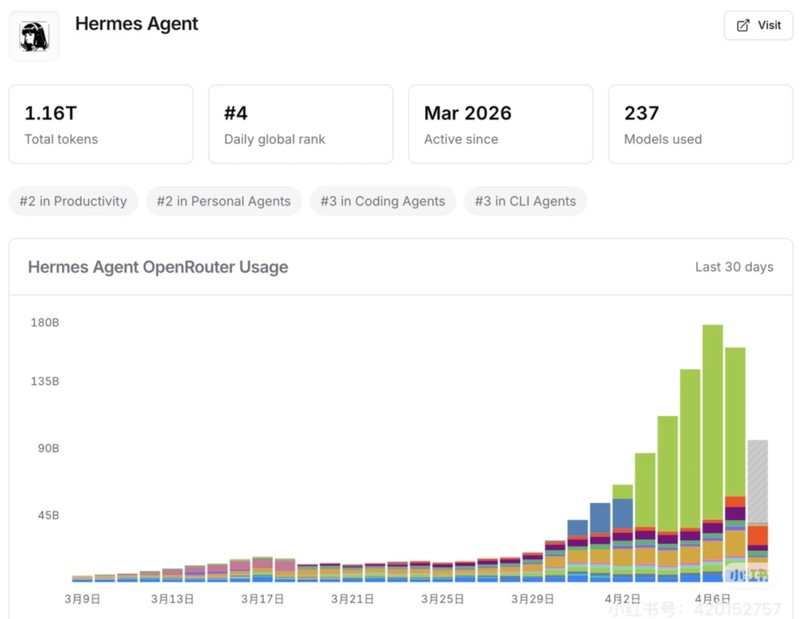
从狂热到理性的回溯
第一次听说OpenClaw是去年底。彼时它的技能生态、渠道接入能力确实让人眼前一亮,多个平台一套系统搞定,这种便利性几乎让我立刻投入了怀抱。但随着项目规模扩大、用户使用周期拉长,一些之前被掩盖的问题开始浮出水面。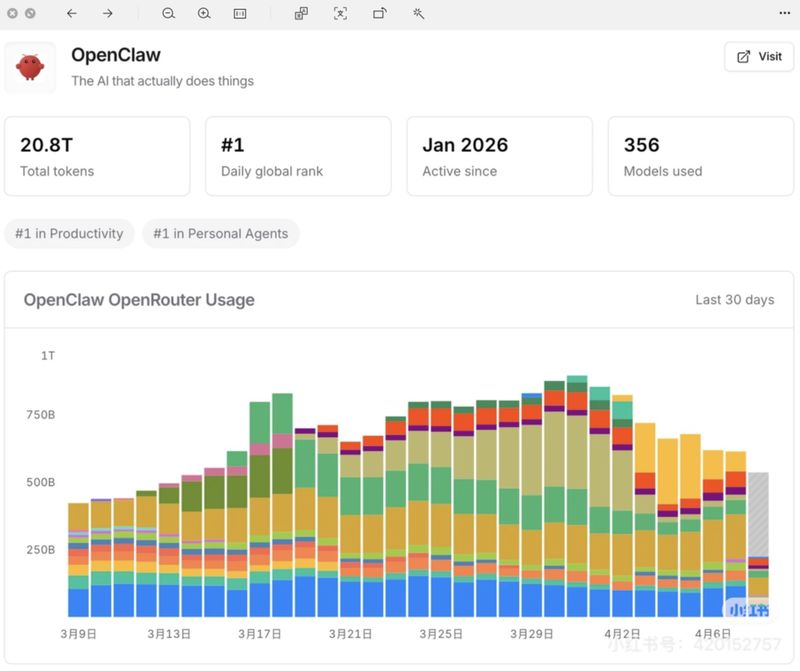
最直观的是上下文膨胀。一次普通查询动辄携带十几万token,按API定价折算下来,单次任务的推理成本已经逼近订阅价格的十倍。这个数字让我不得不停下来重新审视整个架构。
技术瓶颈的几个关键节点
回过头整理,有三个节点特别关键。第一,OpenClaw的Gateway架构在快速扩展生态时优势明显,但复杂度会随接入渠道和技能数量不断累积,当需要定制化深度记忆能力时,改造成本急剧上升。第二,全量存储的策略在初期信息不丢确实让人安心,但当对话历史积累到数千条时,检索效率和token消耗开始形成双重压力。第三,多模型切换虽然技术上可行,实际落地却需要大量适配工作,官方推荐的Claude深度绑定策略与当时ClaudeAPI政策收紧的时间点恰好重合。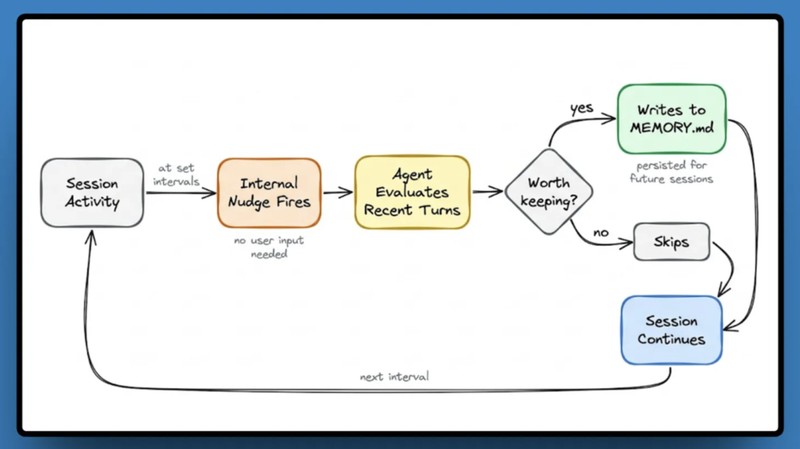
就是在这样的时间窗口里,我开始系统性研究Hermes。
技术架构的实质性差异
对比之后发现,两者的差异不是功能列表的增减,而是底层设计哲学的分歧。OpenClaw的核心是Gateway——连接和协调,把多个入口汇聚到调度中心再分发。这个架构适合快速扩展,但在长期运行的记忆管理和成本控制上存在结构性挑战。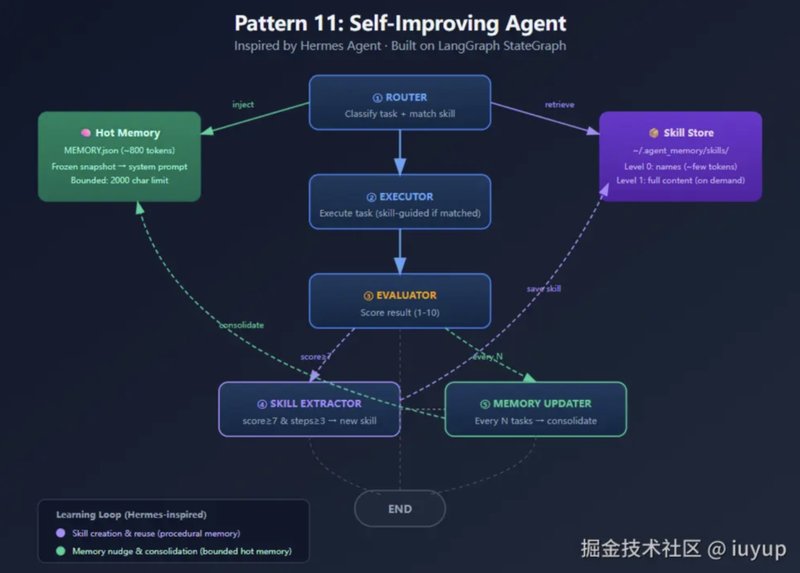
Hermes选择的路线完全不同。它的核心是Agent自身的执行循环,官方称之为闭环学习循环。技能不是预先编写的功能模块,而是由Agent在任务完成后自动生成的结构化文档。这意味着使用时间越长,Agent积累的专属操作手册越完善,重复任务的工具调用次数会自然压缩。
记忆设计的差异更具代表性。OpenClaw采取全量存储策略,信息不丢但噪音随时间指数级累积。Hermes反其道而行,有意为长期记忆设置上限,MEMORY.md和USER.md的字符数被严格限制。这种约束迫使Agent学会信息筛选和压缩,只保留真正有价值的记忆。
从工程视角的方法提炼
实际迁移过程中,有几点经验值得提炼。模型解耦方面,Hermes从设计之初就把多模型切换作为前提条件,目前支持18家以上的LLM提供商,切换成本极低。这个特性在当前模型快速迭代、各家能力此消彼长的背景下尤为重要。
关于学习曲线的担忧是真实的。Hermes的任务状态管理、长流程稳定性、第三方集成生态与OpenClaw相比还有明显差距。但对于愿意投入时间构建长期运行系统的开发者而言,它提供的价值曲线与OpenClaw有着本质不同。
应用场景的适配判断
我的判断是:如果需求是快速搭建多渠道bot、追求即时可用,OpenClaw的生态优势依然明显。如果目标是一个能持续学习、越用越懂用户的长期助手,Hermes的设计哲学更契合这个目标。
两者并非非此即彼的选择。现实路径往往是组合使用:OpenClaw负责多渠道消息路由,Hermes承担核心推理与记忆引擎。这个分工逻辑比“谁取代谁”的叙事更贴近实际需求。
